
Weathering the storm


Some of you might have noticed that we haven't posted an article in a while, and for good reason! In this article I (Tom) will dive into what caused this mishap, and what kinds of measures have been taken to ensure it doesn't happen again.
The joys of self-hosting
As you know by now, we've been putting so much effort into developing our custom tool called Crane It, that helps us deploy all our web services to AWS. We've been using it in production for the past few months now, testing it out to make sure it is as robust as possible. About 3 weeks ago, we started to notice that one of the apps we'd deployed for a client was crashing regularly. This was barely noticeable for them, but was concerning for us. At the same time, our Ghost website (this is the tool we use to write and publish these articles), was randomly deleting some of our articles just after we'd finished writing them. So I set out to find (and hopefully fix) the issue at hand.
CPU spikes
This problem coincidently happened just after we pushed a new feature to production on Crane It (a way to manage point-in-time backups for our servers, meaning that we could now reset an app and its data to the way it was at a previous time easily). So naturally the search began there.
Looking at the analytics we had for our servers, I stumbled upon this CPU (the server's processor) usage spike. Something was causing our instance to overconsume resources, crash, and then reboot. It turned out two of our services were trying to access a file at the same time, therefore causing the server to panic (computers can be dumb sometimes...).
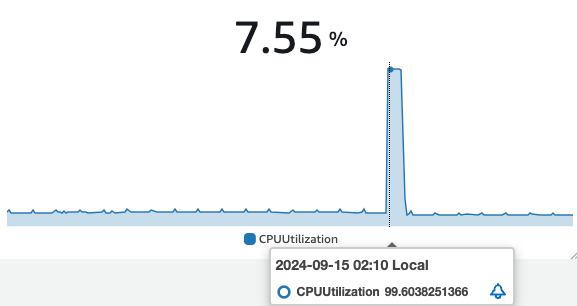
In order to catch this bug, the method was pretty simple: trace back all the elements that were changed during the last update, and study whether each one could be the culprit.
This advice isn't only true for computer science, but also for most challenges in life.
The memory leak
However, it turned out this was only the tip of the iceberg, and that this problem was hiding a way bigger (and darker one).
Having fixed the previous issue, I was expecting the servers to stop crashing. But they didn't. The CPU usage spikes were gone, but the behavior was still there, in a more erratic fashion. The only hint I had to go off of, was a warning message from AWS, indicating high memory usage just before the server would shut down (and yes, to notice this I had to keep a tab open on my second screen all day long, as the log would disappear once the server eventually crashed).
So I decided to start logging RAM (memory) usage, and here is what I found:
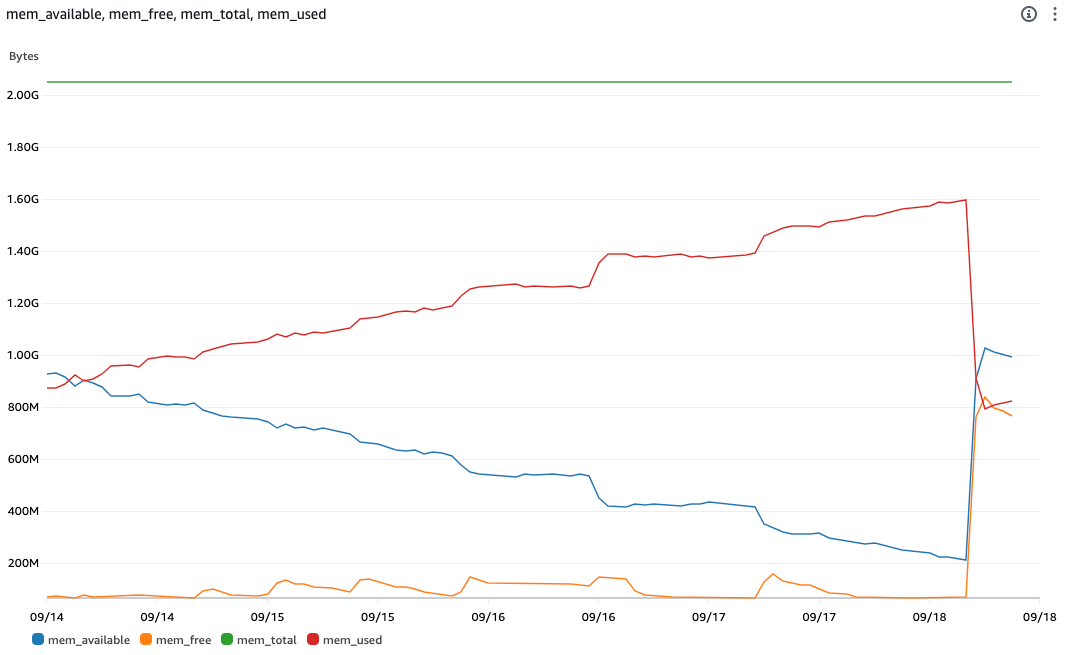
As you can see, the memory usage would steadily increase, until eventually reaching a high value (between 80 and 100%), and crashing the instance.
I'll spare you the details of the debugging process, as it was extremely long and painful. The reason being I had to wait for more than a day in order to figure out if a change had worked or not, as the memory leak needed time to develop. For reference, each of these lines represents a different test (and this is just over a three-day period).
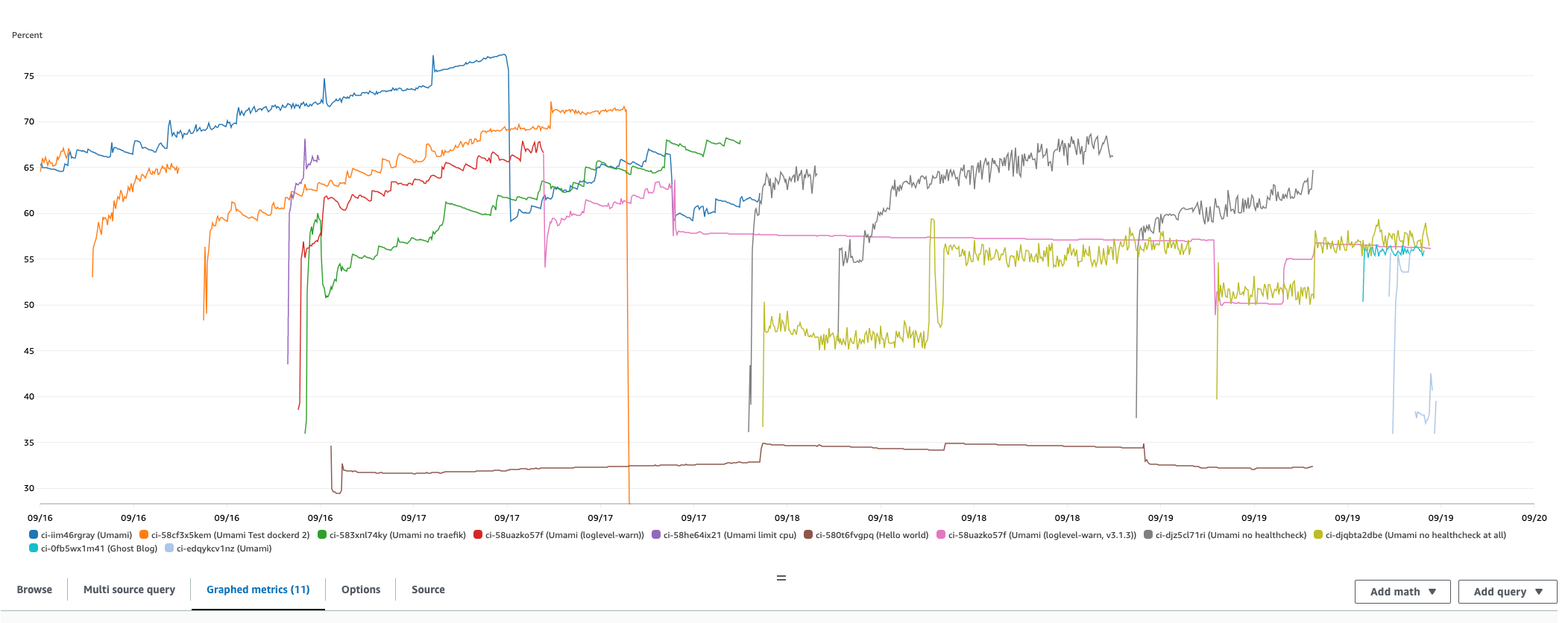
You can see the point in time where I finally found the issue on the pink line, when it suddenly started to stabilize. The problem was due to a current bug in a major piece of software we use: Docker. The entire Crane It project is based on the use of this tool, so this was extremely hard to figure out. Plus, you never expect the bug to come from one of the most widespread pieces of code out there! In the end, it just so happens that, ever since a recent update, one of the 200+ configuration options that docker offers (the heath checks) leaks memory over time.
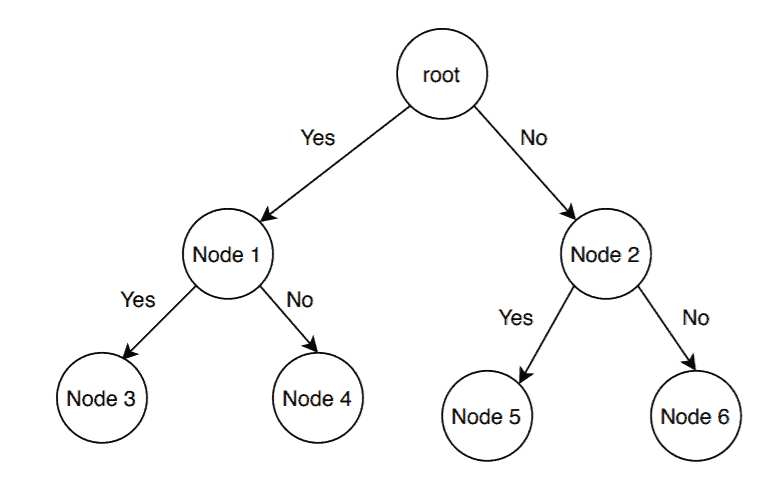
The debugging process was very different to that of the CPU issue. In order to find the leak, the idea was to disable / enable features one by one, until the behavior would change. Two tests could only have one difference that separates them, in order to instantly know what effects the leak or not. This is called Branch and Bound problem-solving, as is a powerful tool in computer science. Here is an example of how this method works, where each node represents a change you've made, and whether it worked:
Having fixed the issue, we are now back on track, with a new and improved (more resilient) version of Crane It. Hopefully this didn't impact any of our clients, it just broke our newsletter for a few weeks.
Stateless applications
From a technical standpoint, we are moving to a stateless architecture from now on, meaning that no persistent data should be stored on our servers (everything must be in an external storage source, like an S3 bucket, or a database). This prevents any issues similar to the ones discussed in this article from ever bothering us again, whilst also making all our apps scalable and resilient to failure. Sadly, this means we'll have to discontinue supporting projects like Ghost, as they don't comply to this principle.
That's it for today folks, if you liked what you read, feel free to share it around to other people who might like it too! See you next week !


